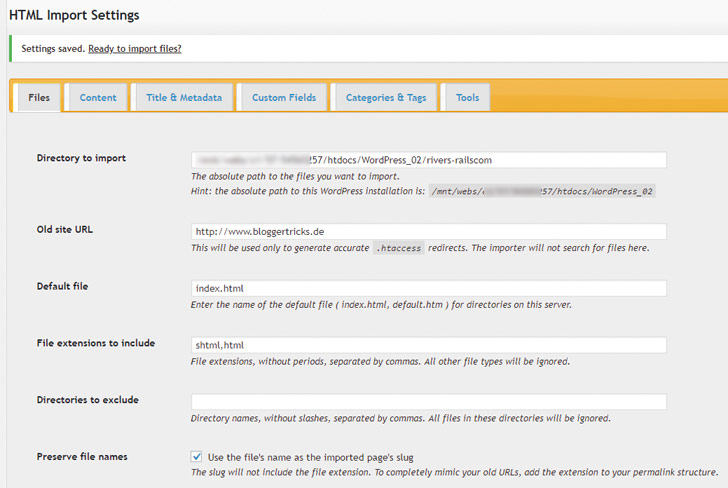
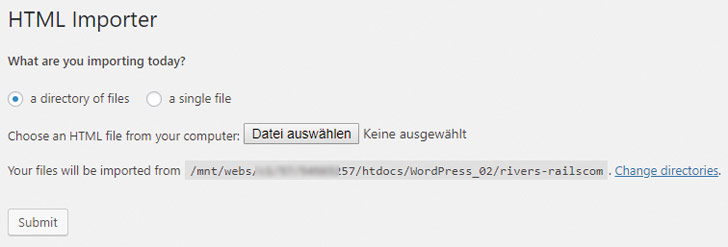
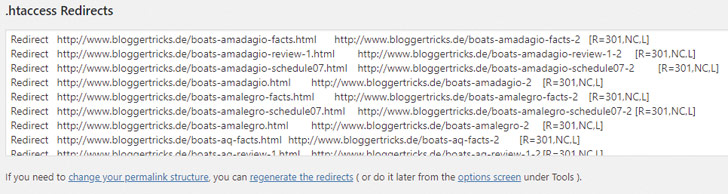
Im ersten Teil des Workshops hast Du den vorhandenen Content für den Import nach WordPress vorbereitet. Um den Import mit Hilfe des Plugin „Import HTML Pages“ https://wordpress.org/plugins/import-html-pages/ tatsächlich zu vollziehen, benötigst Du den Content in Form von statischen HTML-Dateien.
Besteht Deine alte Website bereits aus statischen HTML-Seiten, kannst Du diesen Schritt überspringen und direkt zum Importieren in Teil 3 übergehen. Wahrscheinlich nutzt Du aber auch bisher schon ein Content Management System (CMS), sodass Du statische Seiten draus erst exportieren oder erzeugen musst.
Wichtig: Lege immer zunächst ein Backup der alten Website an, sodass Du alles wiederherstellen kannst, wen in den kommenden Schritten etwas schief laufen sollte.
Im einfachsten Fall hat das CMS eine HTML-Export-Funktion. Lese dazu am in der Hilfe-Funktion oder Dokumentation des CMS nach, wie man die Export-Funktion nutzt. Wenn das CMS keinen HTML-Export bietet, musst Du ein wenig tricksen und den Content mit einer Desktop-Software grabben – also wie mit einem Browser abrufen und lokal speichern.
Website grabben mit HTTrack
Das beste Tool dafür ist die kostenlose Software HTTrack https://www.httrack.com/, die es für Windows und Linux gibt. Für Mac OSX existiert ein passendes Macport- oder Homebrew-Packages. https://www.httrack.com/page/2/
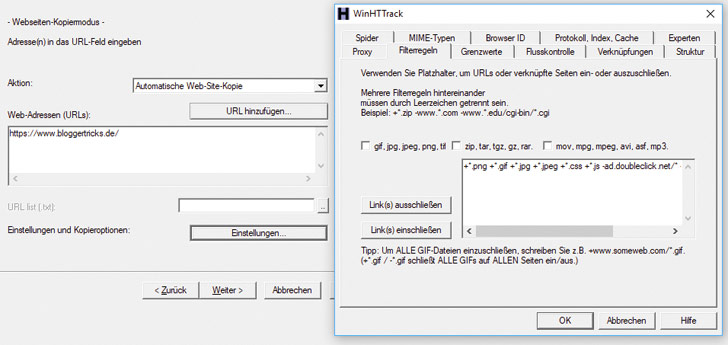
HTML-Seiten grabben mit HTTrack
Die Software ruft die Seiten Deiner alten Website auf wie ein Browser und speichert die dabei erzeugten HTML-Dateien auf Deine Festplatte. Wie Du eine Website mit HTTrack grabbst, findest Du in der folgenden Kurzanleitung, exemplarisch für Windows.
Website grabben mit HTTrack für Windows
Starte WinHTTrack https://www.httrack.com/
Trage einen beliebigen Projektnamen ein.
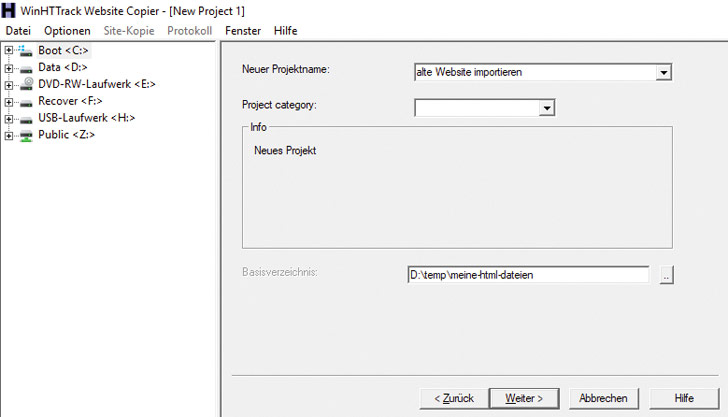
Neues Projekt in HTTrack anlegen
Lege als Basisverzeichnis einen Ordner auf der Festplatte fest, in dem die HTML-Dateien gespeichert werden sollen
Klicke auf weiter
Wähle die Aktion: Automatische Web-Site-Kopie
Gib unter Web-Adressen die URL der Homepage der zu grabbenden Website ein. Wenn Du möchtest, kannst Du stattdessen auch unter URL-List eine Text-Datei angeben, in der alle zu kopierenden Seiten einzeln als URLs aufgelistet sind. Das ist sehr nützlich, wenn der Grabber aus irgendwelchen Gründen mit den normalen Einstellungen zu viel oder zu wenig Seiten grabbt.
Klicke auf den Button Einstellungen
Wähle den Reiter Filterregeln
Nach einem Klick auf den Button „Einstellungen“ kannst Du im Reiter „Filterregeln“ , bestimmte Datei-Typen und Dateipfade explizit ein- oder ausschließen. Wie das geht, zeigt die Hilfefunktion des Tools direkt in dem entsprechenden Reiter. Gegebenenfalls musst Du hier ein wenig experimentieren, um das gewünschte Ergebnis zu bekommen. Sinnvoll ist, diverse fremde Domains auszuschließen, beispielsweise googlesyndication.com, wenn Du Adsense-Anzeigen auf der Website verwendest. Tipp zum Vorgehen: Probiere dass Grabben erst einmal mit Grundeinstellungen aus. Werden falsche oder zu viele Seiten erfasst, kannst Du im laufenden Betrieb abbrechen, die Filter verfeinern, ergänzen und es erneut probieren.
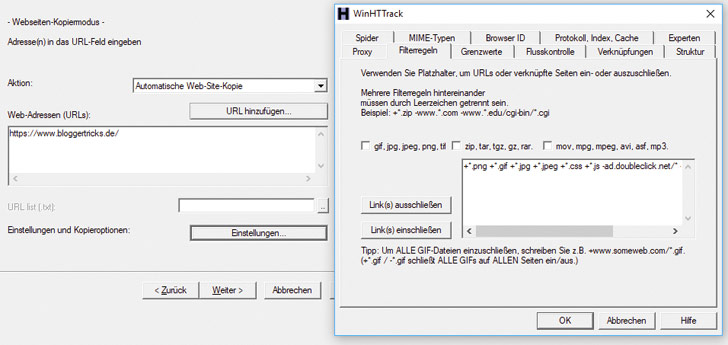
Filter-Regeln in HTTrack
Wichtig: Im Reiter Struktur wählst Du Strukturtyp = „Site-Struktur (Standard)“ und deaktivierst das Häkchen vor „Keine externen Seiten“. Denn HTTrack klassifiziert alle URLs, die mit einem Domainnamen beginnen, als external, auch Deine eigene Domain – mit dem Ergebnis, dass ausschließlich die Startseite gegrabbt wird.
Bei Grenzwerte und Flusskontrolle kannst Du HTTrack nötigenfalls anweisen, nicht die volle Bandbreite Deines Internet-Zugangs fürs Grabben zu nutzen oder das Grabben auf eine bestimmte Zahl von gleichzeitigen Verbindungen zu drosseln.
Unter dem Reiter Browser ID wählst Du HTML-Fußzeile = none
Klicke jetzt auf weiter und dann auf Fertig stellen.Jetzt beginnt der Grab-Vorgang, der je nah der Größe Deiner Website eine Weile dauern kann.
Wenn HTTrack fertig ist, klicke auf Kopierte Seiten anzeigen. Dann siehst Du im Browser die lokale Kopie der Website, die Du eben gegrabbt hast. Kontrolliere genau, ob alles da ist, was Du brauchst. Achte darauf, dass Du beim Verfolgen von Links in diesen Dateien nicht versehentlich auf der Original-URL im Internet landest und daher fälschlicherweise annimmst, diese Seiten seien lokal vorhanden.
War der HTML-Export aus Deinem alten CMS beziehungsweise das Grabben mit HTTrack erfolgreich, bist Du nun vorbereitet auf den eigentlichen Import nach WordPress, den der Workshop in Teil 3 beschreibt.